全新功能
立即訂閱Yahoo!E保網推播通知,隨時掌握各種保險知識及各項最新活動&優惠訊息!

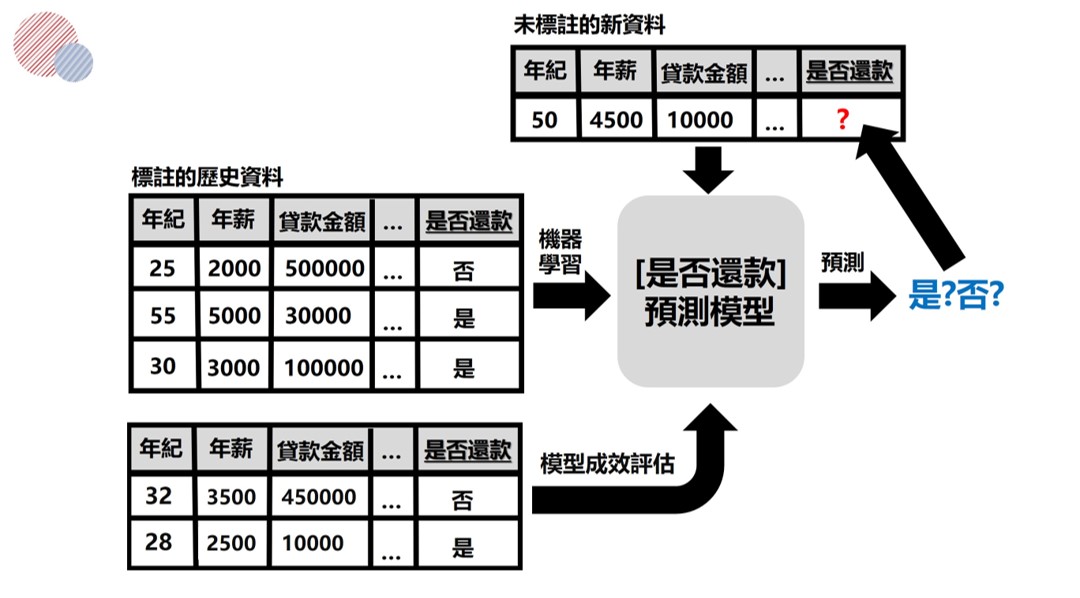 圖一 機器學習的分類模型進行預測
圖一 機器學習的分類模型進行預測 圖二(A)二元分類模型評估混淆矩陣(B)合成資料方法
圖二(A)二元分類模型評估混淆矩陣(B)合成資料方法立即訂閱Yahoo!E保網推播通知,隨時掌握各種保險知識及各項最新活動&優惠訊息!
網路服務專線:0800-366-168
|
服務時間:週一至週五 上午8:30 ~ 下午5:30 (國定假日除外)
客戶服務專線:0800-050-119
|
24小時全天候道路救援及事故現場服務
|
地址:台灣台北市104南京東路三段130號8-13樓
Copyright ©2019 新安東京海上產物保險股份有限公司 All rights reserved, 本網域(yahoo.ebo.tmnewa.com.tw)之服務,由「新安東京海上產物保險股份有限公司」所擁有和提供,請見詳細說明
